
Accidentally Superhuman Systems
or, how to make your customers arm-wrestle a grizzly bear

This is a post about AI risk from a development process perspective. Specifically, how strong AI can end up in places where users don’t expect it, and how open-source AI can turn out to be stronger than an application’s developers anticipated.
Chess on a plane
A year or two ago I was on a plane, flipping through the in-flight entertainment options. I found a chess app. It was quite basic; three difficulty levels, pick one, play against a chess bot. No indication of how strong the bot would be.
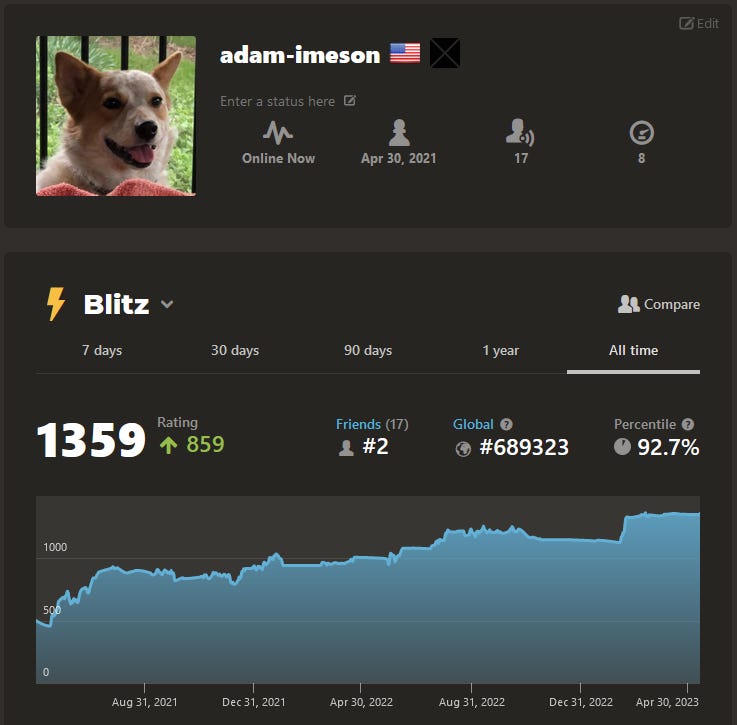
I played a few games against the easiest difficulty and got absolutely demolished in every single one. I like to play against chess engines of varying difficulty, and I know what it feels like when I’m playing against one that is stronger than I am. This engine was significantly stronger.
That was a bit of a surprise. I’m nothing special at chess, but at the time I was in the ~50th percentile for skill (1000-ish Elo rating), according to Chess.com’s stat tracking. And that’s across the population of people with Chess.com accounts, who (one would hope) are better at chess on average than the population of people who buy airline tickets.
I would have expected a reasonable chess app developer to choose a lower-strength chess bot that I might actually be able to beat. What’s the point of a chess app where most people can never win a game?
Naturally, I started to consider how the developer might have chosen the bot. It occurred to me that whoever developed the chess app might not have understood just how powerful chess engines can be!
How powerful can chess engines be?
Nowadays you can get strong chess engines for free online, and they don’t need fancy hardware to run. Modern chess engines playing at their maximum capacity are invincible, as far as humans are concerned.
Here’s Hikaru Nakamura, who is among the top ten-or-so best chess players to have ever lived, discussing his nonexistent chances of beating Stockfish, the strongest chess engine in the world:
This commenter summed it up well:

How to accidentally deploy a strong engine
It would be trivial for normal enterprise software development processes to put Stockfish into a plane’s seatback chess app. There is always the standard bureaucratic project-management game of telephone, where the people implementing the code are removed from the people assessing the code, who are themselves removed from their customers.
There is also the fact that minor decisions made by a single developer can have major impact on the final customer experience. That is, a single line of code, written with a moment’s thought by a single developer, can change every moment of every customer’s experience with the product. In modern software development much of the work is dedicated to processes for testing and approvals, which exist to mitigate that problem. They make a typo less likely to blow up an expensive satellite or send money into the void. But sometimes it’s appropriate to cut corners for the sake of expediency. An airplane chess application is exactly that kind of low-stakes environment.
Modern chess engines implement lower difficulty levels with parameters like uci_limitstrength or uci_elo. If you were writing code to initialize the engine, you might type uci_elo=1300 somewhere in that code, and that is how the engine would “know” it’s supposed to play a lot worse than its maximum strength. This is easy to typo, and it’s also easy to omit, in which case the engine will probably default to its max strength.
Hypothetical scenario:
An airline needs entertainment software for their new fleet of planes. They contract it out to a software development consulting firm.
That firm hands the “in-flight games” portion of the contract to a team of half a dozen developers. The contract requires 10 different games, one of which is chess.
One dev, who isn’t much of a chess player, gets assigned to develop the chess app on a tight deadline.
The dev slaps it together in a few weeks, using a free chess engine they found online (such as Stockfish). They don’t adjust the engine’s difficulty because they don’t know any better. This difficulty setting is the single crucial line of code, given a moment’s thought, by a single developer.
Someone spends a few minutes playtesting the chess app. All of the pieces move legally, and when they get checkmated it goes back to the menu correctly. “Looks good to me!” they say. The dev moves on to their next task.
Months later, the software ships. No one has paid much attention to the chess app because it’s a tiny corner of the entertainment suite.
Airline patrons who try the chess app always lose. Some of them post about it on Reddit, asking if anyone else got their ass whooped by a certain airline’s chess bot.
I want to emphasize that everything I just said is hypothetical. Except for the Reddit threads about an airline putting a Stockfish-tier engine into their chess app. Those are real.
Large Language Models
Just like everyone else, I’ve been thinking about AI large language models (LLMs) like ChatGPT. It’s easy to draw parallels between LLMs and chess engines. They’re both AI tools that exhibit behaviors once thought to be exclusive to humans. It remains to be seen whether LLMs or their descendants will ever exhibit superhuman characteristics, but I don’t think we can rule it out.
Even merely-human writing is still a powerful force in a way that chess-playing could never be. Consider constitutions, religious texts, wartime speeches, hate speech, recipes for explosives, political propaganda, love song lyrics.
LLMs are going to crop up all over the place. For example, game developers everywhere are already trying to figure out how to use LLMs to write dialogue on the fly for computer-controlled characters.
And similarly to chess engines, the going strategy for customizing LLMs is to simply constrain the output of a general-purpose LLM. LLMs are trained on massive corpuses of text scraped from the internet, so a general-purpose LLM tends to be pretty good at generating all kinds of objectionable content.
So if an airline decides to make a game where you can have a conversation with an LLM-powered non-player character as you play, they’re probably going to use a general-purpose LLM and then configure/prompt the LLM to respond as though it were a the desired personality type. And here, again, we have that single line of code, written by a single developer, which everything hinges on!
Imagine an update happens where the “don’t be racist” setting wasn’t configured. Imagine an update happens where the “don’t explain how to synthesize illegal drugs” setting wasn’t configured. If you’re putting an LLM into your application, you need to think about ways to test new versions of your LLM before putting them into production.
Nothing, Forever
Of course, this failure case has already happened. “Nothing, Forever” is an AI-generated Seinfeld spoof that runs live on Twitch, 24 hours a day. The dialogue is generated by an LLM, and then synthesized to voices with a text-to-speech AI tool. Scene changes happen every so often. The characters randomly walk around in low-res 3D-modeled sets as they natter on endlessly with each other. The show is generated in real time.

“Nothing, Forever” went viral in February as LLMs were starting to go mainstream. The show was going well. Tens of thousands of viewers were tuning in to see this novel form of entertainment. And then the LLM that was generating the dialogue crashed.
The show ground to a halt. The developers behind the show scrambled to set up an older backup version of the LLM, and quickly got the show back up and running. Shortly after, one of the AI-generated characters started making transphobic jokes, and the channel was temporarily banned from Twitch. Thus ended the viral novelty.
It turned out that the backup LLM didn’t use the same content moderation capabilities as the newer, primary LLM. Its output was significantly less constrained, which resulted in output that emulated the darker corners of its internet-sourced training data. Similar to a chess engine being accidentally left at its maximum strength, this LLM was accidentally configured to speak on its maximum breadth of topics.
In conclusion
I’m looking forward to hilarious articles about LLM-powered systems saying outrageous things in unexpected contexts.
If you know how to make sure that LLMs don’t say the wrong thing, you can probably make a lot of money in the next few years. There will be huge demand for automated integration tests that provide high confidence that a given LLM configuration will produce business-friendly output.
And if LLMs turn out to be superhumanly good at persuasive writing, then I hope an airline’s video game character doesn’t accidentally talk me into starting a new religion while I’m bored on a flight.